In the latest (September 2007) issue of Game Developer, my old slave driver during my Neversoft days, Mick West, wrote a nice article about responsiveness in games. One thing Mick’s article covers in quite some detail is input latency and how this latency changes between a game running at 60 fps and at 30 fps.
The whole 30 vs. 60 fps issue is a timely one (no pun intended) that is probably discussed at just about any game developer making games for the PS3 and the 360, due to the difficulty of hitting 60 fps (which is unarguably better than 30 fps, when attainable) while still having what’s considered to be next-gen graphics. It’s certainly a topic that has come up at our office more than once, shall we say.
There were two things that Mick didn’t cover in his article that I wanted to touch upon here. The first one is that his presentation didn’t talk about frame scanouts potentially taking longer than 1/60th of a second. Just to make it clear: I’m not talking about the interlacing issue of fields vs frames here. Even for progressive scan we could have scanout taking longer than a frame. The reason is that certain TV’s do post-processing of the image to do god-knows-what (convert between resolutions, remove sparkling pixels, run sharpening filters, etc) which easily can introduce one or more frames of delay. There really isn’t much to be done about this sort of built-in delay other than to purchase a TV that has a “game mode” (e.g. a Toshiba 52HMX94 and probably several other, newer TVs) which disables all the fancy post-processing, etc. that cause delays. Also, make sure to use a HDMI cable, where applicable.
However, the other thing Mick didn’t really touch upon is something we can do to reduce the lag, namely restructuring how the game loop and the rendering is done.
Lag at 60fps
Before we get to the crazy stuff, let’s examine what things look like with a traditional game and rendering loop, running at 60 fps. In the following I’ll assume we have a TV capable of 60Hz scanout, just like Mick did. Also, in the following, when I say “frame” I always mean a frame at 60Hz.
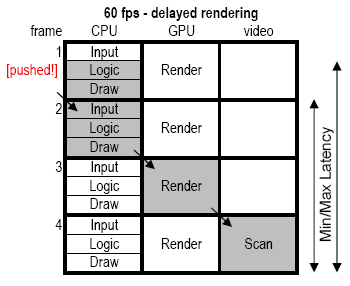
The above figure is more or less identical to the one in Mick’s article, showing 4 frames (at 60Hz) and how processing flows from CPU to GPU to the screen. The difference in my illustration is that it highlights both the maximum latency (shaded in gray, which happens when input occurs at the time indicated by the red next) as well as the minimum latency (shown only by the smaller vertical arrow to the right).
Best-case for 60 fps we get a 3 frame lag and worst-case we have a 3.67 frame lag (assuming input and logic each take 1/3 of a frame to run).
Lag at 30fps
The reason more and more people are aiming at 30 fps instead of 60 fps is because we get to use the GPU for twice as long, and for next-gen graphics the GPU is invariably the bottleneck so more GPU time is a good thing (many would argue a necessary thing). But, alas, the input latency increases when we go to 30 fps, as the figure below illustrates. (BTW, in this figure I’ve assumed input and logic still takes 1/3 of a frame (at 60Hz) to run. That’s perhaps not entirely accurate, but it makes for better comparisons.)
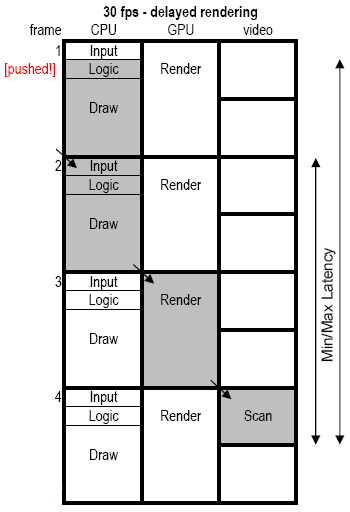
Looking at the figure we see that best-case for 30 fps is 5 60Hz-frames of lag, and worst case is 6.67 frames of lag. Compared to 60 fps, we have introduced between 2 and 3 frames of lag, for the price of much improved graphics.
Intermission
Here it may be worthwhile to stop and point out that running at 30 fps in practical terms actually more than doubles what you can draw over running at 60 fps! “What? How can that be?! Christer is crazy!” you say. Hardly! Crazy like a fox perhaps. You see, let’s say 1/3 of the frame at 60 is spent drawing HUD, doing post-processing, and other fixed overhead. That leaves 2/3 of a frame for drawing game objects. Running at 30 fps, we still have 1/3 of a frame for fixed stuff, and 1 2/3 frames available for drawing game objects. 1 2/3 divided by 2/3 is 2.5, so we can actually draw 2.5 times as many game objects, with everything else the same!
Okay, so I’m a little bit sloppy in equating 2.5 times as much time to draw objects with 2.5 times as many drawn objects, and perhaps we’d do a little extra post-processing, but you get the point: realistically we can do more than twice as much at 30 fps than we can at 60 fps. Who is crazy now, huh?!
Reducing the latency
So, we can render more stuff at 30 fps, but we paid for it with longer latencies. Can we reduce the latency somehow? We can, by switching from delayed rendering to immediate rendering! With delayed rendering (to distinguish it from deferred rendering) I mean the practice of preparing a whole draw list on one frame and have it render on the next. What we’ve talked about above, in other words. Immediate rendering would be when we issue draw calls right there, on the spot. Naively changing the drawing code to be immediate we get the situation illustrated below.
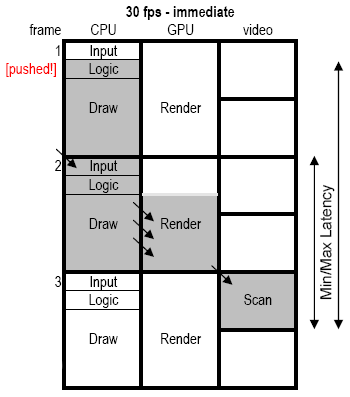
The first thing we notice is that we’re no longer utilizing the GPU 100%. But, hey, we’re still getting more than just a frame’s worth of GPU, and the latency is now down to 3 frames best-case (same as at 60 fps) and 4.67 frames worst-case (which is one frame more than at 60 fps, but one frame less than at 30-delayed rendering).
For this to work well, it is important for the CPU to produce draw calls faster than (or at least as fast as) the GPU can consume them. If not, the GPU would just be used spuriously within the 1 1/3 frames and the effective GPU utilization would probably be less than a frame, at which point this approach would be, er, pointless.
“That’s interesting Christer,” you say, “but even at full utilization, 1 1/3 frames of GPU isn’t enough.” And, yes, you’re right, it isn’t. We really want the whole two frames. So, let’s shift things around a bit and see what happens. Instead of synchronizing for vertical blanking (VBL) at the start of the game loop code, lets put the VBL sync just before the drawing code on the CPU. This results in my final figure.
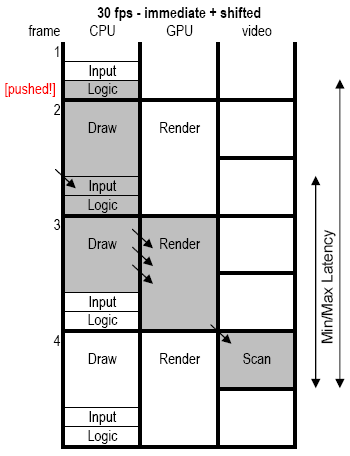
We now have the logical game frame start roughly halfway into the 30Hz-frame (exactly when it starts depends on how long it takes to finish the CPU drawing for the previous game frame). Note that I’ve drawn the GPU utilizing all of its time for rendering, continuing beyond the spot where the CPU stops issuing draw calls. This is okay, because we’ve already assumed the CPU is issuing draw calls faster than the GPU can consume them, so some will have been batched up, meaning the GPU will continue on. Furthermore, we almost always end a frame with a lot of fullscreen passes, and these are fast to issue on the CPU but may go on for several milliseconds on the GPU.
Note also that in order to facilitate switching to the new front buffer, we need to set up a VBL interrupt to do the switching, as the CPU code is no longer guaranteed to be idle at around VBL time (as it is with the delayed rendering approach).
The input latency is now 3.67 frames best-case and 5.33 frames worst-case. Compared to the 30 fps-delayed rendering (where the same numbers were 5 and 6.67 frames, respectively) we have reduced lag by around 1 1/3 frames overall by going with immediate rendering.
Should we go crazy?
That’s a seemingly respectable decrease in lag, so do I recommend people switch to immediate rendering at 30 fps, with a shifted game loop? Um, no, probably not. It’s a big change, it’s untested (or, at least, I’m not aware of anyone doing rendering this way), you need to ensure your CPU draw code is fast enough so as not to starve the GPU, etc. Basically, it’s really taking a plunge in the deep end. Also, arguably, while trained game developers might notice the difference in lag (for certain types of games) it is not clear that most game players would notice the improvement. All in all, it seems like a risky move that could leave you worse off if you’re unlucky.
However, I wanted to post about this topic anyway, because I love to see some comments on this blog post. Do you think what I outlined would work for real? Have you or someone you know done anything simular? Any other ideas for reducing input lag? How important is it to reduce input lag anyway, and why? Feedback please!
Very interesting Christer. You’ve almost described spot on how the renderer works for us. We used to have what you described as delayed rendering, but had to switch to immediate rendering (or single buffered rendering as we called it) due to memory considerations. Delayed rendering basically requires you to have all the resources that the command buffer live and locked while the GPU works. Which in lazy world :) translates into buffering all your dynamic content. We also saved a lot of command buffer space since we could reuse parts of the buffer that had been consumed.
I had one question about the diagrams though. The logic part seems awfully small, that could easily be expanded to fill the whole frame. One way to solve that is to decouple the simulation of the game and the command buffer generation, but that kind of implies another frame of lag there. 1/3 of 60fps is approx 5.6ms which isn’t a whole lot :) to do all your logic. Maybe you could break this up in just feedback logic and the rest of the game simulation… hm… seems a little bit tricky.
Hi Jim. Yes things aren’t necessarily exactly to scale. I just wanted to focus on the drawing bit so I made the logic be the same for 60 fps and 30 fps (which isn’t entirely unreasonable), and logic was 1/3 of a frame for the 60 fps case purely for ease of drawing! I think you answered your own question though: decoupling the simulation directly equates to more lag. Mick talked about that in his Game Developer article.
Hi Christer, Jim!
I really enjoyed this post, which made we want to expand on it by talking about how simulation fits in. (http://meshula.net/wordpress/?p=109) Here’s the meat of it –
in a multiple CPU scenario, there is in fact one more frame of delay that can encrue. If there is simulation going on, such as particle physics, smoke, and other such systems that don’t need to show instantaneous response to input, it’s possible to put that work on another CPU, and have it lag the game itself by a single frame.
Similarly to your diagram, light blue indicates the shortest possible latency between user input and display. Yellow indicates the maximum latency between a user input and display, this being the case where the user performed an input in the Logic segment of Frame 1. Green indicates the latency of simulation to the display, and red indicates the worst case latency of simulation that reacts to user input from a previous frame.
Nonetheless, having simulation as a separate process has a major advantage, in that heavy simulation work can proceed at its own pace and not block the critical draw segment which must always run faster than the GPU. It also allows an obvious way to leverage multi-core or multi-processor systems. The disadvantage of this is that resources such as texture or vertex buffers may need to be double buffered.
Consider the calculation of a water surface. If the water is simulated in frame 2 in the diagram, it will be submitted to the GPU in frame 3. During that period, the vertex buffer is likely to be locked, so in order to calculate frame 4’s water during frame 3, a second buffer is necessary in that period. An advanced technique is to put fences and syncs into the Draw segment. The fence would be injected immediately after the submission of the water surface in the Draw segment. When the fence is hit, the water simulation could be unblocked and it could recycle the vertex buffer as long as it is guaranteed that the simulation and buffer rewrite can be finished before the Render needs it again. A sync in the Draw segment just before the submission of the water surface would synchronize the simulation thread to ensure that the thread is done with the water surface.
Ideally, in this advanced scenario, the simulation and render are interleaved such that thread synchronization occurs incredibly rarely allowing all processors to speed at maximum throughput. Our later internally developed PS2 titles worked this way.
The submission engine architecture I talk about in other posts on my blog leverages this structure. The submission engine tracks a persistent draw list in order to leverage frame to frame coherency to minimize the amount of CPU time consumed by the Draw segment. The submission engine double buffers the draw list so that the creation of the next draw list can occur while the present one is being processed. This further leverages multi-core/multi-processor systems by reducing hard dependencies between segments.
(sorry, I couldn’t make the diagram show up in the post… It’s at http://i148.photobucket.com/albums/s29/meshula/FrameLatency.jpg )
We used the “30 fps delayed rendering” technique almost exactly as you described. That’s the same schedule as the PS2/XBox games I worked on, too. Automatically getting 100% GPU utilization was very important for those titles. Although you use more command buffer space, it does simplify many things– your CPU renderer doesn’t need to be optimized for latency within a frame or keeping the GPU fed, it just has to finish generating all GPU commands for a frame in the budgeted time.
I think that the immediate rendering method would work well to improve latency, at the cost of some amount of GPU utilization. That’s not really the direction I want to be heading :) but if the latency was an issue that would be a good way to improve it.
The worst case for the delayed rendering technique uses between 83 and 111 ms of lag. That’s not much over the 100 ms threshold where you start to notice lag (I’ve always heard that 100 ms was the noticeable threshold, I assume that’s true?). You do have to be careful to not introduce any more latency, though, such as polling input at the wrong time, or putting another frame of delay between the game sim and rendering. For us, the latency was close enough to 100 ms that anything else causing lag was noticeable.
You’re right about the lag. Between a user forming an intention, such as “press the button”, and the button actually getting pressed, there is a delay on the order of several tens of milliseconds. This delay is a result of the fact that neural signals travel at about fifty kilometers an hour, and have got a distance of around a meter to traverse, and proprioception requires a round trip to signal that the finger has felt the push. Our minds have already factored this delay into our perceptions, but it is one of the primary causes of games feeling mushy – we perceive that the proprioceptive loop is closed (we feel that we wanted to push the button, and that the button was pushed), but our eyes see the lag of the action on the screen and that sensory disconnect results in the mushy feeling. An amusing side note is that the size of a baseball field naturally matches this inherent round trip latency – the distance of the pitcher to the batter is just larger than the speed of thought quite literally (coupled with the ability of the human musculature to accelerate the bat – 45m/s vs 18m = 400ms). The distance of a soccer penalty kick to the goalee is actually just smaller than the speed of thought + reaction time, which I think reflects the character of the gameplay!
Nice article Christer. Immediate mode rendering is indeed a method of reducing latency. But only around a “frame”‘s worth. It’s also a bit more complex than deferred rendering, for the reasons you mention – but also because you generally have to establish draw order before you submit anything to the GPU. Due to the huge difficulty in switching rendering models, one would be best advised to look at simpler fixes first – such as the analysis of the flow of the button press event through the main loop.
Nick’s response, above, on the physiological factors seems a little off the mark. Like he says, the mind has already factored in the delay from the proprioceptive loop, and so the only important (perceptible) factor here is the additional lag. The proprioceptive loop itself is not a reason why games feel mushy. They would feel equally mushy if the proprioceptive loop had a zero latency.
Thanks for the gdmag article Mick, it was very thought provoking!
To clarify my statement a bit, I’m attributing the mushy feeling to the sensory disconnect caused by lag (which is no different than what you’re saying), and am suggesting that the proprioceptive delay is a factor that contributes to the mushy feeling. I agree, my statement is rather off the mark, I’ll moderate my stance on “primary” to simply “contributing”, that seems much more on the money and a much more balanced statment :)
(Modified my post to take Mick’s feedback into account and give credit)
I was thinking about the last immediate+shifted example that you mentioned. In that example, just before the CPU Draw began, you sync’d to the vblank. It seems that the CPU game thread could sync on any interval occuring at 30 hz– could you sync just before the CPU draw, but at the vblank minus (say) five milliseconds?
That would give the CPU a head start of 5 ms to guarantee enough work was queued for the GPU to get full utilization. You could actually use any shift value; in a sense, the delayed example is using a shift of 33.3 ms (two vertical blanks) to keep the GPU fully fed, but that’s surely more time than is needed.
Improving the button flow through the main loop is going to help the latency more than this, but this might help a 30 fps game that still felt mushy.
“could you sync […] at the vblank minus (say) five milliseconds?”
First, if you could, you’d be adding five (or whatever) milliseconds to your input latency, but let’s assume that’s fine. As to whether you actually could, well, remember that every other VBL we will be flipping front buffers (or similar). That means the GPU rendering (to a single backbuffer) must lie fully within two VBLs. If you start the CPU drawing at vblank minus 5 ms, you need to somehow ensure that you don’t start issuing immediate draw calls until after the vblank, 5 ms later. That might be doable, but seems messy. You would effectively need a second sync inside the CPU draw code then, so your CPU draw call would look something like:
I think that’s right, or am I missing something?
“you’d be adding five (or whatever) milliseconds to your input latency”
Yes, you’d be saving about five milliseconds less than the 1 and 1/3 frame latency of the immediate+shifted example. On the other hand, you’d give the CPU a head start so it could fill up enough commands to keep the GPU busy 100% of the time.
“You would effectively need a second sync inside the CPU draw code then”
Almost– I actually meant that the CPU only syncs once at VBL minus five. However, the GPU does sync itself at the VBL. This can be done by queueing into the command buffer something like SetWaitFlip(), which stalls the GPU (not CPU) until the next flip, or having the GPU wait for a fence set in the VBL interrupt.
The CPU game loop would look like:
Sync to VBL minus 5 ms
SetWaitFlip()
Prepare (batch up) some draw calls
Loop { Input; Logic; SyncToVBLMinusFive; SetWaitFlip; Draw; } until done
I think that works, but I haven’t tried it.
Interesting topic. I remember that David Etherton was about the only person I knew that used the FIFO buffer in the PS2 for immediate rendering, instead of building a frame’s worth command buffers, that got kicked off at the next VBL. He did this to save memory. (We blew about 2 Mb on memory to store command buffers, which is a lot on PS2).
Can I ask how people handle sorting of render state in immediate mode rendering? Because we store all render commands and then do a sort before kicking off rendering.
“Almost– I actually meant that the CPU only syncs once at VBL minus five. However, the GPU does sync itself at the VBL. This can be done by queueing into the command buffer something like SetWaitFlip() […]”
That gets somewhat platform specific, but yes, that seems reasonable when the platform supports it. And you’re right that it would be useful to have the 5 ms (or whatever) headstart on the GPU. Thanks for the comments!
“Can I ask how people handle sorting of render state in immediate mode rendering? Because we store all render commands and then do a sort before kicking off rendering.”
Hi Dan, good to see you! We don’t do immediate rendering, but it seems clear that not everything can be truly immediate. The opaque stuff can be, but your translucent stuff, postprocessing, etc. effectively has to be delayed (accumulated into one or more push buffers) until the point where you can actually issue these accumulated push buffers in an immediate way.
Hopefully Jim or Nick can comment on how they do it (and others too, of course). I wouldn’t be surprised if there are some gotchas that aren’t immediately obvious (no pun intended).
(Cross posted to my blog)
If you must support immediate mode rendering in your pipeline, here are some tips for maximizing performance.
Make your primitives as high level as possible
1. Prefer baked shapes to procedural primitives.
2. Prefer procedurals to strips or point batches
3. Prefer strips or point batches to quads, quads to tris.
For example, HUDs are often drawn with immediate or immediate-like rendering. If you can, bake the HUD so you can submit it as a single primitive. If the HUD has a highly variable part, try baking all of it except for the variable part, and have that have a fixed data size so you can just blit in what you need.
If you must support submission of arbitrary lists of primitives, collate the primitives into baked buffers; don’t submit individual primitives to the driver except as an extreme last resort (even in OpenGL).
Treat text blocks and particle systems as single primitives. Maintain a single buffer or set of buffers, and recycle it. There will be an optimal size for this buffer that is a tradeoff between your application’s requirements and hardware/driver performance. Profile often.
If you have a shape that you will re-use for several frames, bake it.
If you frequently use some shape like a disc, parameterize it, and blit it into your render stream as a high level disc primitive.
Use the notion of materials, never the fixed function pipeline (don’t use a model of the FFP either!)
– The driver will maintain an internal state machine tracking your operations versus its internal state which represents a virtual model of the fixed function pipeline. In general all this state tracking is expensive.
– You need to minimize the state changes that are costly – and you will need to measure the hardware to find out what is actually slow. Don’t trust what you read in a book or found on the web. It changes frequently.
– Create immediate mode materials that are blocks of expensive state change. Submit these blocks to the pipeline in chunks; don’t do it in dribs and drabs.
– Order your renders to minimize invocations of these blocks. For typical immediate modes, you might be able to boil these materials down to a small set such as “unlit, untextured”, “unlit, textured”, “lit, textured”, “shiny lit, textured”, “unlit, alpha transparency”.
– You also need to know the cost of a texture bind. Depending on whether texture bind or other state change is more expensive you will need to order your draws by texture then sub-order by material, or material then sub-order by texture.
Create an “unbind” material that creates a state change block that undoes the immediate material bind so that you don’t mung things up for the rest of your pipeline.
– All the materials should touch all of the same state.
– Only issue the unbind material before you revert to non-immediate rendering.
– Assign each material a number. Order the numbers such that moving from one material to the next in sequence touches the fewest pipeline states. (You’ll see why when we get to the keys.) Here, we are relying on the driver internal state tracking to help us minimize the cost of material binding.
Figure out what restrictions you can live with, and pick your restrictions for speed.
– If your application can get away with a text draw, and textured screen facing quads, support only that, and make it screamingly fast.
– So many things you think you need immediate for, such as manipulator axis, you can trivially do another way with baked geometry. If you can bake it, do!
– The immediate pipeline is your last resort.
Divide your rendering into phases. These phases are highly dependent on what you need your render engine to do to support your game. Typical phase breakdown might be
z-depth pre-pass, non-alpha geo, alpha-geo, post-passes, composite, HUD
Assign a key to each batch of immediate renders. A typical 32 bit key might look like this (where 0 is the MSB):
0-3:phase// 4-11: material// 12-16: texture// 17-31: rough z
– highest order bits to indicate render phase
– a few bits to indicate material
– a few bits to indicate a texture page in VRAM
– the rest of the bits for rough z-order. If you want to use early z-depth, make low numbers near the camera. If you need back to front ordering for painters’, then use high numbers near the camera
Use sorted submission lists using the key and merge sort during just in time final push to hardware as discussed earlier in the Input Latency thread. If you can keep the submission lists persistent from frame to frame, a radix sort works well for the individual lists before the merge sort. I am assuming that the rest of you render engine is similar broken into phases in order that the immediate lists can be interleaved with other incoming draws from other threads.
Note that not all immediate rendering needs to be accumulated in submissions. The non-alpha geo phase in particular can be submitted interleaved with regular rendering for minimal latency. Unless you want to insert fences and syncs into your pipeline, all other order dependent phases will need to be accumulated into buffers. Fences and syncs can help you minimize RAM usage because the pipeline can demand that the engine cough up render requests at the right time, but you run the risk of stalling everything.
On some architectures, you can chain in render primitives without copying the data into a GPU queue; in that case you’re golden because you can just make DMA thread through all your drawing. The major caveat there is to make sure the data isn’t discarded or overwritten until the DMA has chased past its end. With careful structuring, you can save large amounts of memory for things like water surfaces if you can queue up the next frame of simulation for the precise moment the DMA is done with the last frame’s vertices.